
讓電腦理解人話的技術-自然語言處理,在我們的生活中早已無處不在。從語音助理 Siri 到逛網站時所跳出的輸入建議與廣告,機器無時無刻都在設法理解我們的一言一語。本篇文章將使用淺顯易懂的方式解釋 NLP 技術 - AI 模型是如何理解人類語言的。
2020 年時,由 Elon Musk 所創立的國際 AI 組織 Open AI 公布了最新的 AI 寫作程式 GPT-3 ,其近乎於人類的問答與寫作能力霎時造成廣大的迴響。你是否會好奇,究竟電腦是如何理解人類語言的呢? 底下將會以簡單的方式解釋電腦理解與回覆人類語言的基礎原理。
AI 人工智能如何理解我們的語言?
人類理解語言的方式是先拆解成一個一個字詞,並依過去的經驗來判斷字詞組合所要表達的意思。然而,在電腦的世界裡並沒有文字,有的僅是一連串代表各式含意的文字。也因此,電腦必須得將接收到的文字轉換成數字。
而像 GPT、BERT 等現今最主流的 AI 技術,會將文字轉換成向量這種形式來讓機器理解文字。至於什麼是向量呢? 簡單地說,向量可以想像成是一條穿越次元的直線。
什麼是向量?
那到底向量是什麼呢? 我們先來看最簡單的直線 :
這條直線是我們在國小的數學課上最常接觸到直線。由於這條直線只有左右一種方向,因此被歸類在成存在於一維空間的直線。
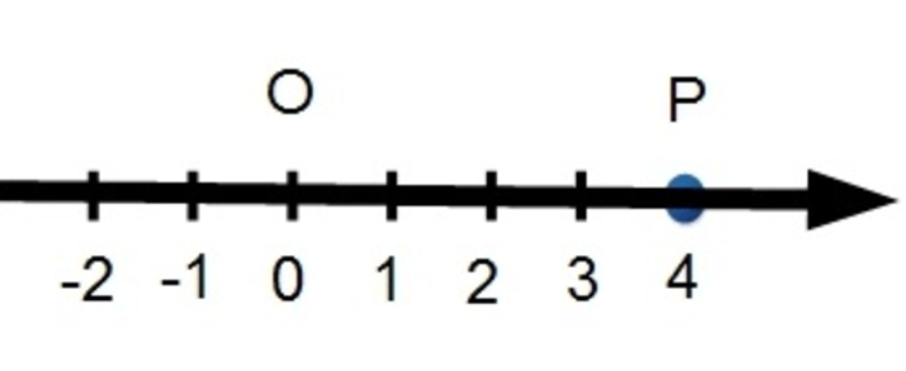
在數學上,我們會用一個數字來表達,這條直線會被標記為 (4) 。如果今天存在一條兩倍長的直線,則可被標記為 (8) ;方向相反的話則為 (-8) 。
接著我們看下面這張圖 :
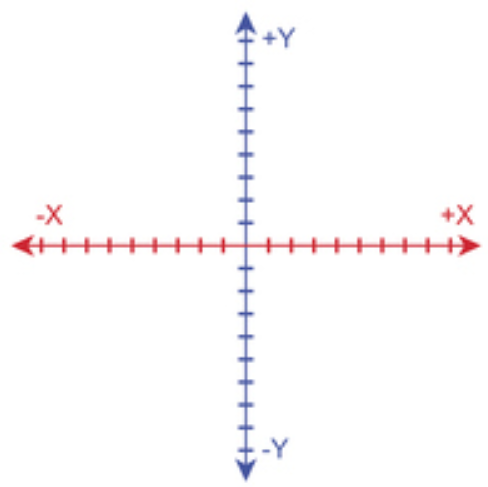
上面這張圖是我們在國中階段時時常接觸到的直線圖 ,由於除了左右外,又多了上下兩個方向,所以被稱為二維空間的直線。也因此,在數學表達上,我們會用兩組數字來表示它。若有一條線從原點指向 X = 3,Y = 4,這條線被我們標記為 (3, 4) 。如果要計算它的長度,我們可以用國中學過的三角形勾股定理計算而得 : 3^2 + 4^2 = 5^2,長度為五。
以此類推,如果將空間概念拓展成我們日常生活的三維空間 (長寬高) 的話,數學向量就會用三組數字來表達這條直線的方向還有長度 :
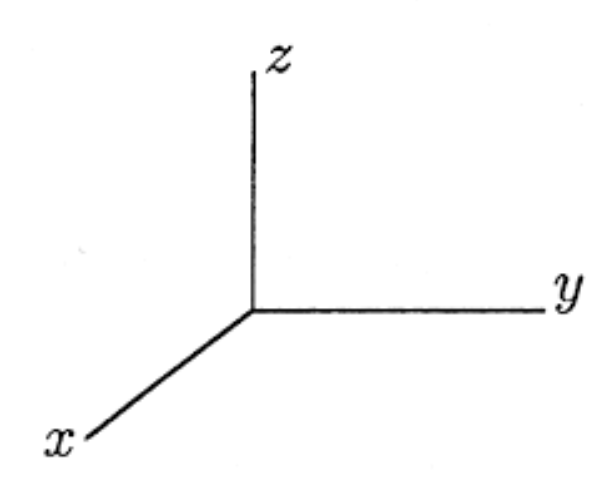
那如果是四維空間呢? 由於我們活在三次元的生物,三維以上的空間我們既看不到,也摸不著,自然很難用圖形表達出來。但在數學向量上,卻可以很輕鬆地辦到,我們僅須用四組數字便可輕鬆表示四次元的直線。
也因此向量可以想像成是一條穿越次元的直線,不論多少維度空間的直線,我們都可以用數學向量簡單表示。而現今主流的 AI 模型正式使用高維度的向量來理解文字語言的。
NLP 是如何使用向量代表語意的?
人類的大腦可說是世上最為複雜的系統之一,而由人類文化所衍生出的自然語言,比起程式語言來說,也同樣複雜不少。為了刻劃語言的複雜性,現今主流的自然語言處理 NLP (Natural Language Processing) 模型都以高維度的方式呈現每個文字,文字與文字間的關聯性則使用大量參數來做加減乘除等運算。以 BERT 來說,一個中文字在模型內會以 1024 與 768 兩種維度的向量表示,而文字與文字間的運算參數量更是高達一億以上。
向量與參數是如何運算產生的?
為了產生出足以代表文字意涵的向量與文字關聯性的參數,首先我們會給予 NLP 模型大量的文字庫來學習,模型首先會給予每個文字初始向量與參數,隨後對文字進行隨機挖空與破壞,模型必須得透過挖空破壞後的文句來預測出原本的文字結構。一但模型能準確預測出挖空破壞前的文句,就代表它成功掌握了代表文字的向量與參數。
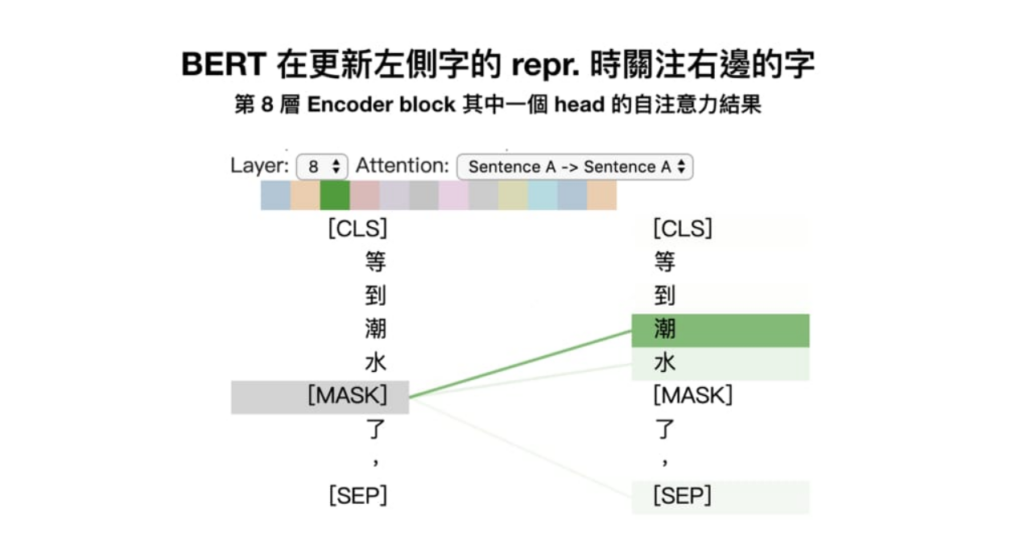
而透過觀察,我們能發現到 NLP 模型學習後,相似的文字在向量空間上有聚集在一起的傾向,代表著向量數字確實能反映出文字字義的特性。
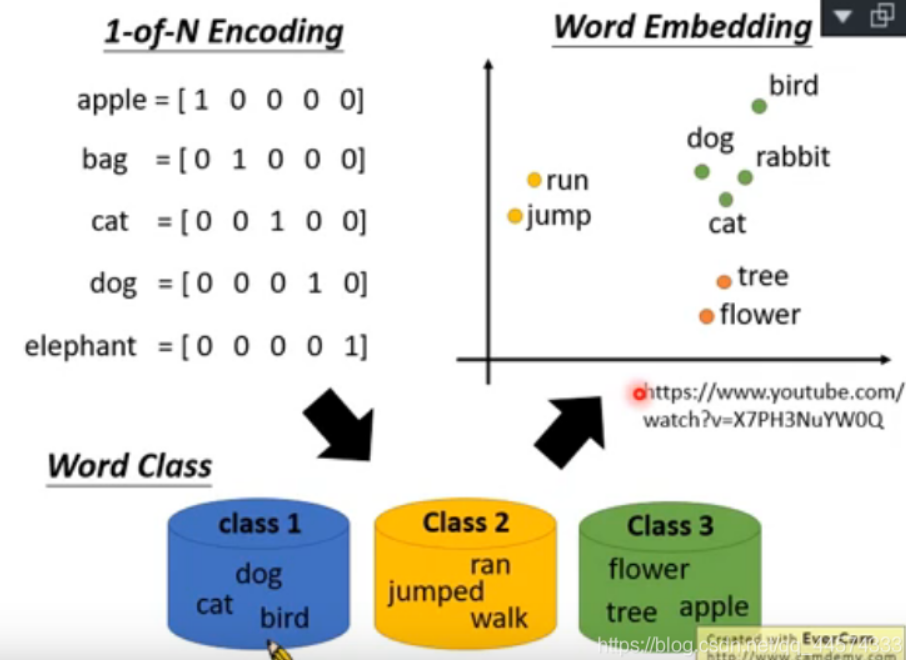
用 PYTHON 程式語言實作 NLP 向量的幾種方式
(1) Glove
Glove 是早期常見的 W2V (Word to Vector) 技術,能將使用者所準備的文字轉化為文字向量。模型會同時預測出現字詞與出現頻率。
(2) Fast-Text
Fast-Text 是 Meta (FB) 在 2016 年所推出的 NLP 神經網絡模型,該模型同樣能用快速簡易的方式
將使用者準備的文字庫轉化為文字向量。
(3) BERT
BERT 是由 Google 所推出的 NLP 遷移學習模型,也是現今最被普遍使用的 NLP 技術,使用的參數與資料規模也比上述兩項大不少。我們能透過拆解 BERT 的預訓練模型來取得已訓練好的文字向量。

