這次會使用兩項新的工具進行爬蟲,分別是:
puppteteer 是甚麼?
Puppeteer是一套基於NodeJS的工具庫,它提供了一個高級 API 來通過 DevTools 協議控制Chromium,而且Puppeteer和Chromium都是由Chrome官方團隊來維護的
跟cheerio不同的是,cherrio只能做靜態爬蟲,而puppteteer可以模仿人類做輸入,按鈕...等
Puppeteer 的功能有哪些?
- 生成頁面的截圖和PDF
- 爬取SPA應用(單頁應用程序),並生成預渲染內容(即“SSR”服務端渲染)
- 用作爬蟲去抓取網站內容
- 創建最新的自動化測試環境。使用最新的 JavaScript 和瀏覽器功能直接在最新版本的 Chrome 中運行測試。
- 創建一個自動化測試環境,並運行相關的測試
- 追踪網站的時間線,用以分柝不同部份的性能問題
- 測試 Chrome 擴展程序。
怎麼開始使用?
首先,在編譯器裡輸入下面指令並開始使用它:
npm i puppeteer這裡如果是第一次下載,可能會花比較多時間,因為它會一併下載Chromium,等一下爬蟲機器使用的瀏覽器是Chromium。
基礎的puppteer怎麼寫?
關於puppteer的基礎使用示範:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch(); //打開伺服器:Chromium,
const page = await browser.newPage();
await page.goto('https://ranking.works/WordPress%E6%95%99%E5%AD%B8');
await page.screenshot({ path: 'ranking.png' }); //將Url截圖並存成ranking.png
await browser.close();
})();如果想看到Chromium打開的畫面可以在launch裡面加上{ headless: false},變成
const browser = await puppeteer.launch({ headless: false });,就會看見這個畫面:
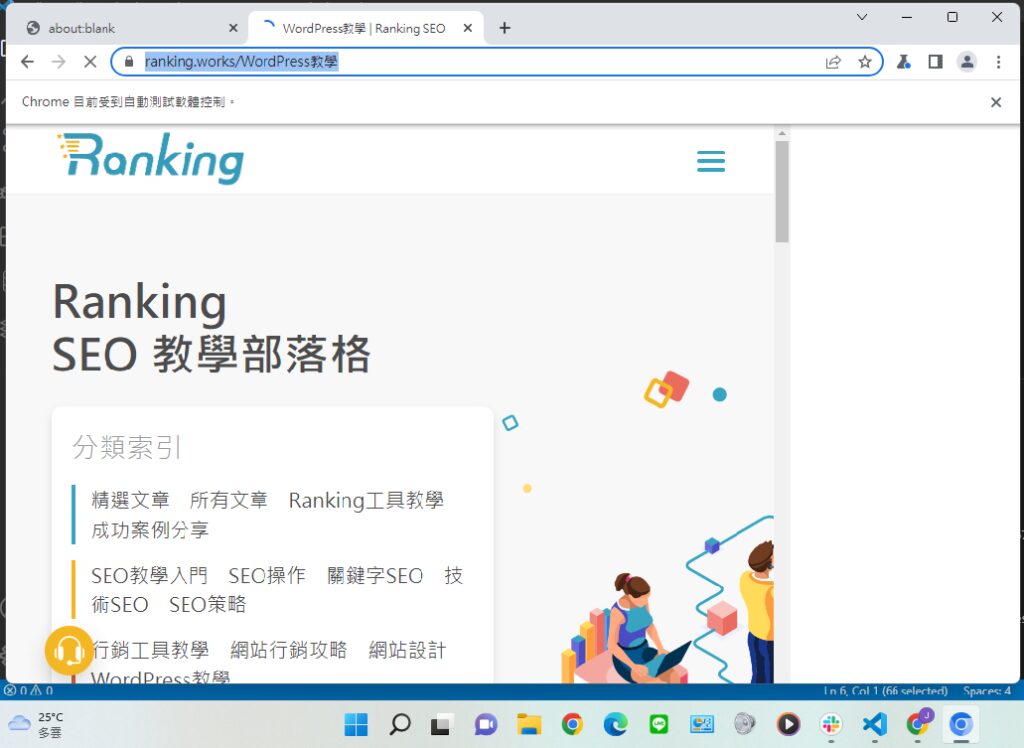
這個就代表機器打開了瀏覽器並進入了這個url(https://ranking.works/WordPress%E6%95%99%E5%AD%B8)。
最後當你結束了爬蟲任務,用完後關閉瀏覽器(也可以不關,它就會開在那邊)。
總結一下剛剛發生了:
- 打開瀏覽器
- 開啟新的分頁
- 進入特定的網址
- 截圖,把圖片存下來
puppeteer page的常見方法有哪些?
在puppteer對網頁的操作都會在page之中,操作有以下的功能:
page.goto(url[, options]):直接進入特定的連結頁面page.$(selector):選取特定元素,等同於 document.querySelectorpage.$(selector)page.$eval(selector, pageFunction[, ...args]):對於選取的元素進行特定行為,如取出元素的 HTML 屬性值。page.$$eval(selector, pageFunction[, ...args]):前者的複數型page.click(selector[, options]):點擊特定的元素page.type(selector, text[, options]):在特定的元素上輸入文字內容,通常是 input 上輸入page.select(selector, ...values):在 select 元素上選取特定的值page.waitForSelector(selector[, options]):等待頁面上的特定元素出現,在非同步的過程中很實用。
怎麼開始爬蟲??
不同於之前的文章,這次沒有使用cheerio而是只有puppeteer ,所以語法會有些不同(但差不多意思)
首先使用page.$(selector)去抓取需要的資料集合:等同於之前的document.querySelectorAll
之後使用迴圈,,並在迴圈內選擇要爬下來的資料:
最後輸出爬到的資料
範例程式碼與成果影片
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage(); // 開啟新分頁
await page.goto('https://www.google.com.tw'); // 進入指定頁面
await page.type('input[title="Google 搜尋"]', 'ranking.works'); // Google 搜尋特定項目
await (await page.$('input[title="Google 搜尋"]')).press('Enter'); // 特定元素上按下 Enter
await page.waitForSelector('#gsr'); // 確定網頁的元素出現
await page.waitForTimeout(1000);
await page.screenshot({path: 'rank.png'});
await page.click('a[href*="https://ranking.works/"]');
await page.waitForSelector('#__layout > div > div.navbar.sticky-top.d-flex.justify-content-between > div')
await page.click('#__layout > div > div.navbar.sticky-top.d-flex.justify-content-between > div');
await page.waitForTimeout(1000);
await page.click('#__layout > div > div.navbar.sticky-top.d-flex.justify-content-between > div > div > ul > li:nth-child(3) > div > div > svg');
await page.waitForTimeout(1000);
await page.click('#__layout > div > div.navbar.sticky-top.d-flex.justify-content-between > div > div > ul > li:nth-child(3) > div.toggle-subMenu > div > ul > li:nth-child(6) > a');
await page.waitForSelector('.col-lg-4.col-md-6.col-sm-6')
const links = await page.$$('.col-lg-4.col-md-6.col-sm-6') //qureyselectorAll
for (const link of links) {
const text = await page.evaluate(element => element.querySelector('.blog_post-title.color-black').textContent, link);
const href = await page.evaluate(element => element.querySelector('a').getAttribute('href'), link);
console.log(`標題:${text}, 網站:https://ranking.works/${href}`)
}
await browser.close();
})();這隻程式總共發生了幾件事
- 打開瀏覽器
- 開啟新的分頁
- 搜尋 ranking.works
- 進入ranking的網址
- 點開ranking的選單
- 點選WordPress教學
- 進行爬蟲
- 將class:col-lg-4.col-md-6.col-sm-6 之中的文字和網站爬下來並輸出
執行影片:

