今天分享一個cheerio 網路爬蟲實作案例
網站:https://www.kva.idv.tw/?Tsoft=1707&p=zsoft
預計將其中的內容整理成下面這樣的格式:
{
"負責人姓名": "王小明",
"診療機構名稱": "愛心動物醫院",
"電話": "0987654321",
"地址": "台灣"
}會使用到的套件有fetch、cheerio、iconv
先透過fetch取得資料,由於網頁是用big5編碼,需用iconv decode
最後透過cheerio或許需要的資料。
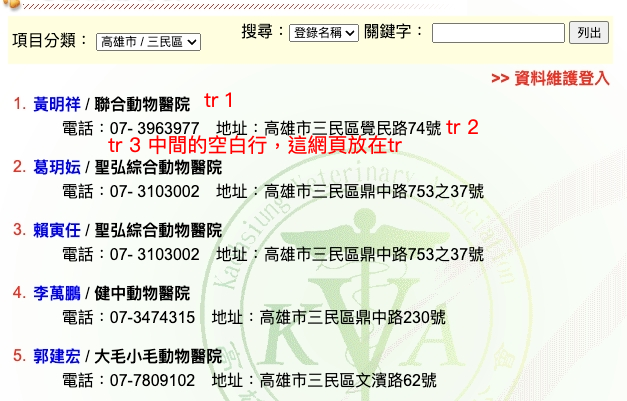
第一步:先分析網頁架構

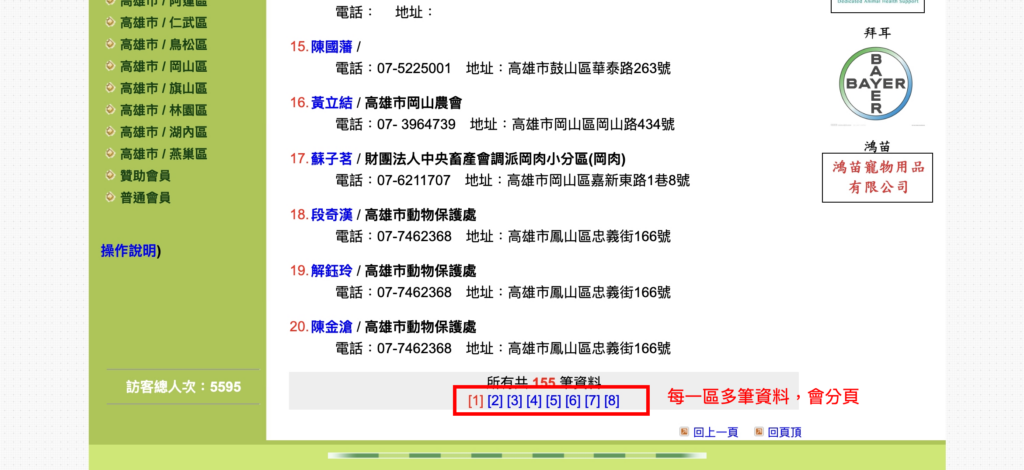
我先嘗試抓取某一區單一頁的資料,程式碼如下:
const cheerio = require('cheerio');
const fetch = (...args) => import('node-fetch').then(({default: fetch}) => fetch(...args));
const iconv = require('iconv-lite'); //解決big5問題
//針對單頁內容進行爬蟲
async function crawler(url){
const response = await fetch(url); //取得網頁內容
//因使用big5,要用iconv decode
const buffer = await response.arrayBuffer();
const decode = iconv.decode(Buffer.from(buffer), 'big5')
const $ = cheerio.load(decode);
//取得tr的list,長度為61
const list =$('body > table > tbody > tr > td > table > tbody > tr > td:nth-child(2) > table > tbody > tr > td:nth-child(1) > table:nth-child(4) > tbody > tr');
const pageResults = [];
//一頁20筆資料,但有61個tr,每一筆資料間有個空白欄,也是佔一個tr,最後一個tr是頁碼
//因為所有資料都在tr中,所以未使用for of的方式跑迴圈
//用等差數列的思維去決定每一欄位要抓第幾個tr
//i<list.length/3,可以剛好抓滿20筆資料
for(let i=1; i<list.length/3; i++){
pageResults.push({
"負責人姓名": $(list[(i-1)*3]).find('td:nth-child(2) > a > font > b').text(),
"診療機構名稱": $(list[(i-1)*3]).find('td:nth-child(2) > b').text(),
"電話": $(list[(i-1)*3+1]).find('td:nth-child(3)').text().trim().split('地址:')[0].replace('電話:',''),
"地址": $(list[(i-1)*3+1]).find('td:nth-child(3)').text().trim().split('地址:')[1]
})
}
//嘗試打印出來,確認結果沒問題
// console.log(pageResults);
return pageResults //但最終要將結果傳出去以利後續使用
}
for of的方式跑迴圈第二步,分別取得網址
分別取得每區各頁碼的網址,還有每個區域的網址,這兩部分相對單純,邏輯也相仿
// 取得每區個別頁碼的網址page url list
async function getPageNumUrl(url){
const response = await fetch(url);
const buffer = await response.arrayBuffer();
const decode = iconv.decode(Buffer.from(buffer), 'big5');
const $ = cheerio.load(decode);
//取得a標籤列表
const list =$('body > table > tbody > tr > td > table > tbody > tr > td:nth-child(2) > table > tbody > tr > td:nth-child(1) > table:nth-child(4) > tbody > tr:nth-child(61) > td > font > font:nth-child(3) > a');
const PageNumUrl = [];
for (let i of list) {
PageNumUrl.push('https://www.kva.idv.tw/' + $(i).attr('href'))
}
// console.log(PageNumUrl); //檢查內容是否有誤
return PageNumUrl;
}//取得各區域的網址
async function getPageUrl(url){
const response = await fetch(url);
const buffer = await response.arrayBuffer();
const decode = iconv.decode(Buffer.from(buffer), 'big5');
const $ = cheerio.load(decode);
//取得tr標籤列表
const list =$('#webleftarea > table > tbody > tr:nth-child(2) > td > table:nth-child(2) > tbody > tr');
const pageUrl = [];
for (let i = 0; i < list.length-1; i++) {
pageUrl.push('https://www.kva.idv.tw/' + $(list[i]).find('td > a').attr('href'))
}
// console.log(pageUrl); //檢查內容是否有誤
return pageUrl;
}最後一步:組裝程式碼
將上述三個程式碼組裝成一個程式碼
思維流程:先取得各區域的網址list,這個list是每區的第一頁
用網址list逐一個開始進行crawler,但這樣只有每區的第一頁被爬到,所以要再產出該區的其他分頁的page list,在對page list中的每個網頁進行爬取。
產生的程式碼如下:
async function main(){
const pageUrl = await getPageUrl('https://www.kva.idv.tw/?Tsoft=1707&p=zsoft');
let results =[]
for (let i of pageUrl){
results = results.concat(await crawler(i));
const pageNumUrl = await getPageNumUrl(i);
for (let j of pageNumUrl){
results = results.concat(await crawler(j));
}
}
console.log(JSON.stringify(results));
}
main()
